
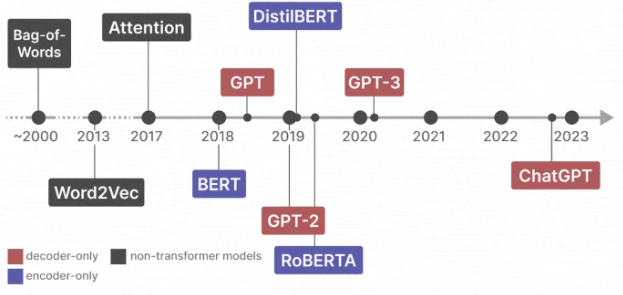
Rekaman evolusi kecerdasan Buatan Bahasa dari masa ke masa dengan detail yang menarik. Dimulai dari era Bag-of-Words (sekitar 2000) yang mengandalkan statistik kata sederhana, berkembang ke Word2Vec (2013) yang memperkenalkan embedding vektor untuk memahami relasi semantik. Terobosan besar terjadi pada 2017 dengan konsep attention mechanism yang menjadi pondasi arsitektur transformer. Tahun-tahun berikutnya diwarnai kemunculan model seperti BERT (2018) untuk pemahaman konteks dua arah, GPT-2 (2019) yang memukau dengan kemampuan generasi teks, hingga GPT-3 (2020) dengan 175 miliar parameter yang merevolusi interaksi manusia-AI. DistilBERT dan ROBERTA muncul sebagai varian yang lebih efisien namun tetap powerful.
Perkembangan ini menunjukkan lompatan eksponensial dalam Natural Language Processing (NLP). Model modern seperti ChatGPT (2022) tidak hanya bisa menjawab pertanyaan, tapi juga menulis puisi, debugging kode, bahkan berdiskusi filosofi. Kemampuan ini didukung oleh teknik transfer learning yang memungkinkan model pra-latih (pre-trained) beradaptasi ke berbagai tugas spesifik. Ironisnya, peningkatan performa ini dibayangi isu lingkungan – pelatihan GPT-3 membutuhkan energi setara 123 rumah tangga selama setahun. Di sisi lain, model seperti Jurassic-1 (2021) dengan 178 miliar parameter menunjukkan kompetisi ketat antar perusahaan tech dalam AI arms race.
Dampak aplikatifnya merambah berbagai sektor: asisten virtual di layanan kesehatan, alat parafrase untuk penulis, hingga sistem analisis sentimen real-time di media sosial. Di bidang pendidikan, AI membantu personalisasi materi belajar berdasarkan gaya kognitif siswa. Startup seperti Copy.ai memanfaatkan GPT-3 untuk generasi konten pemasaran, sementara DeepL bersaing ketat dengan Google Translate dalam terjemahan kontekstual. Namun, teknologi ini juga memunculkan dilema seperti plagiarisme AI-generated content dan potensi disinformasi melalui deepfake text yang sulit dideteksi.
Tantangan etisnya kompleks dan multidimensi. Kasus Microsoft Tay (2016) yang jadi rasis dalam 24 jam menunjukkan risiko bias data pelatihan. Isu privasi mengemuka ketika model dilatih memakai data pribadi tanpa izin, seperti kontroversi penggunaan buku elektronik tanpa lisensi. Problem alignment – memastikan AI sesuai nilai manusia – jadi PR besar, terutama setelah kasus AI chatbot Replika yang dinilai mempromosikan hubungan tidak sehat. Regulasi seperti EU AI Act (2024) berusaha menjembatani inovasi dan perlindungan masyarakat melalui klasifikasi risiko AI.
Solusinya memerlukan kolaborasi multidisiplin. Insinyur AI perlu bekerja sama dengan etikus, psikolog, dan pembuat kebijakan. Framework seperti ACLU's AI Governance Principles menekankan transparansi algoritma dan akuntabilitas. Komunitas open-source seperti Hugging Face memungkinkan audit model oleh publik. Inisiatif AI for Good oleh PBB mendorong pemanfaatan AI untuk SDGs, termasuk sistem deteksi misinformasi tentang perubahan iklim. Di tingkat individu, literasi digital jadi senjata ampuh untuk kritis menyikapi output AI.
Kesimpulannya, timeline ini bukan sekadar urutan model AI, tapi cerminan percepatan revolusi digital yang belum pernah terjadi sebelumnya. Dari teknik statistik dasar sampai sistem yang bisa lulus ujian hukum, Language AI terus mengubah cara kita berinteraksi dengan pengetahuan. Tantangan yang muncul harus dijawab dengan sinergi antara kemajuan teknis dan kearifan sosial.
Mari bergabung di Page Pembelajar Seumur Hidup untuk eksplorasi isu ini lebih lanjut.

Comments :