
Model Optimization: Knowledge Destillation?
Introduction
Salah satu cara sederhana untuk meningkatkan kinerja hampir semua algoritma machine learning adalah dengan melatih banyak model berbeda pada data yang sama, lalu merata-ratakan hasil prediksinya (seperti pada konsep ensemble learning). Akan tetapi cara ini menjadikan model menjadi terlalu besar, terutama jika model yang digunakan adalah neural network besar [1]. Tantangan yang muncul adalah bagaimana menerapkan model besar ini pada perangkat dengan sumber daya terbatas, seperti ponsel atau perangkat tertanam (embedded devices) [2].
Concept
Knowledge Distillation adalah teknik untuk kompresi model, di mana model yang lebih kecil (student) dilatih agar meniru model besar yang sudah dilatih sebelumnya (teacher). Pengetahuan ditransfer dari teacher ke student dengan cara meminimalkan loss function, yang bertujuan agar prediksi student mendekati prediksi teacher yang telah “dilunakkan” dan sekaligus mendekati prediksi label asli (ground-truth). Prediksi teacher dilunakkan dengan menerapkan fungsi temperature scaling pada softmax, sehingga distribusi probabilitas menjadi lebih halus dan menampilkan hubungan antar kelas yang dipelajari oleh teacher [1,3].
Yang dimaksud dilunakkan adalah student belajar tidak hanya benar atau salah dari dataset aslinya namun dari probabilitas hasil tebakan model teacher yang mungkin tidak langsung menebak benar salah tapi hanya probabilitasnya saja. Cara ini membantu model kecil tidak hanya mengetahui jawaban yang benar, tetapi juga seberapa yakin model besar terhadap setiap kemungkinan jawaban [5]. Ilustrasi Knowledge Distillation dapat dilihat pada Gambar 1.
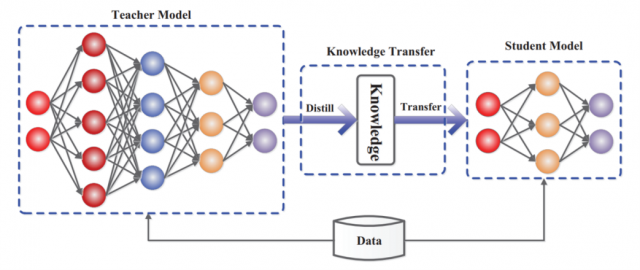 Gambar 1. The generic teacher-student framework for knowledge distillation [2].
Gambar 1. The generic teacher-student framework for knowledge distillation [2].
Architecture
Desain arsitektur student-teacher sangat penting agar proses akuisisi dan distillation pengetahuan berjalan efisien. Mentransfer pengetahuan dari deep neural network tidaklah mudah karena kedalaman dan kompleksitasny. Beberapa arsitektur student model yang umum digunakan untuk mentransfer pengetahuan antara lain:
- Versi lebih sederhana dari teacher model, dengan lebih sedikit layer dan neuron di tiap layer.
- Versi quantized dari teacher model. (Quatized - model atau bobot jaringan dikurangi presisinya misalkan dari angka floating-point ke angka yang lebih sederhana, contohnya dari 32-bit menjadi 8-bit)
- Jaringan kecil dengan operasi yang lebih efisien.
- Jaringan kecil dengan arsitektur global yang dioptimalkan.
- Menggunakan model yang sama seperti teacher.
Selain itu, metode terbaru seperti Neural Architecture Search (NAS) juga bisa digunakan untuk merancang arsitektur student model yang paling sesuai dengan teacher model tertentu [4].
Training
Terdapat tiga metode utama dalam melatih model teacher dan student, yaitu offline distillation, online distillation, dan self-distillation. Pembagian metode ini tergantung pada apakah model teacher ikut diperbarui bersamaan dengan model student atau tidak [4].
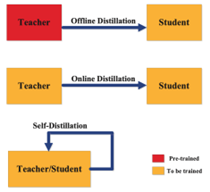 Gambar 2. Types of knowledge distillation training schemes [2].
Gambar 2. Types of knowledge distillation training schemes [2].
- Offline distillation
Offline distillation adalah metode yang paling umum, di mana model teacher yang sudah dilatih sebelumnya digunakan untuk membimbing student model. Pada metode ini, teacher model pertama-tama dilatih dengan dataset tertentu, lalu pengetahuan dari teacher tersebut ditransfer untuk melatih student model. Berkat kemajuan deep learning saat ini, banyak pre-trained model yang dapat didownload dan dapat digunakan sebagai teacher sesuai kebutuhan. Offline distillation merupakan teknik yang sudah mapan dalam deep learning dan relatif mudah untuk diterapkan [4].
- Online distillation
Pada offline distillation, teacher model yang sudah dilatih sebelumnya biasanya berupa deep neural network berkapasitas besar. Namun, dalam beberapa kasus, pre-trained model mungkin tidak tersedia untuk digunakan secara offline. Untuk mengatasi keterbatasan ini, digunakan online distillation, di mana teacher dan student model diperbarui secara bersamaan dalam satu proses pelatihan end-to-end. Metode ini bisa dijalankan dengan parallel computing, sehingga menjadi metode yang sangat efisien [4].
- Self-distillation
Pada self-distillation, model yang sama digunakan sebagai teacher maupun student. Misalnya, pengetahuan dari layer yang lebih dalam pada deep neural network bisa digunakan untuk melatih layer yang lebih dangkal. Metode ini dapat dianggap sebagai kasus khusus dari online distillation dan bisa diterapkan dalam beberapa cara. Pengetahuan dari epoch awal teacher model dapat ditransfer ke epoch berikutnya untuk melatih student model [4].
Keywords: AI, Knowledge Distillation, Teacher Model, Student Model, Machine Learning, Model O
SDG: 9 “Industry, Innovation and Infrastructure”
Referensi:
- E. Hinton, O. Vinyals, dan J. Dean, "Distilling the Knowledge in a Neural Network," CoRR, vol. abs/1503.02531, 2015. [Online]. Tersedia: http://arxiv.org/abs/1503.02531
- Gou, B. Yu, S. J. Maybank, dan D. Tao, “Knowledge Distillation: A Survey,” arXiv, 2021. [Online]. Tersedia: https://arxiv.org/abs/2006.05525
- Borup, “Knowledge Distillation,” Keras Code Examples, Sep. 01 2020. [Online]. Available: https://keras.io/examples/vision/knowledge_distillation/
- Se, “Everything You Need to Know about Knowledge Distillation,” Hugging Face Blog, Community Article, Mar. 6 2025. [Online]. Available: https://huggingface.co/blog/Kseniase/kd
S. Teki, “Knowledge Distillation: Principles, Algorithms, Applications,” Neptune Blog, ML Model Development, Sep. 29 2023. [Online]. Available: https://neptune.ai/blog/knowledge-distillation

Comments :