
Vector Embedding: Teknik Representasi Data Non-Numerik yang lebih intuitif
Dalam machine learning, setiap data perlu direpresentasikan dalam bentuk numerik. Namun, masalah muncul ketika input data tidak selalu numerik. Sebagai contoh, ChatGPT menggunakan teks sebagai input, dan ada banyak kasus lain di mana data input dalam machine learning bukan merupakan data numerik secara langsung. Untuk mengatasi hal ini, terdapat beberapa metode untuk mengubah data non-numerik menjadi numerik, seperti one-hot encoding dan label encoding. Sebagai contoh sederhana, kata-kata seperti "es teh", "es jeruk", dan "pisang" bisa diberi label masing-masing "es teh" = 1, "es jeruk" = 2, dan "pisang" = 3. Namun, pendekatan ini kurang bermakna karena sebagai manusia, kita memahami bahwa "es teh" dan "es jeruk" lebih mirip karena keduanya adalah minuman, sedangkan "pisang" adalah makanan, yang secara kategori berbeda.
Alternatif yang lebih efektif adalah menggunakan embedding atau vector embedding, yang merupakan teknik representasi data dalam ruang vektor laten dengan dimensi yang lebih tinggi. Perhatikan Gambar 1 berikut:
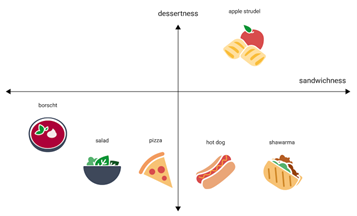
Gambar 1. Embedding Ilustration (Foods plotted by both "sandwichness" and "dessertness.") (https://developers.google.com/machine-learning/crash-course/embeddings/embedding-space)
Dalam metode ini, setiap objek atau informasi direpresentasikan sebagai vektor yang terdiri dari beberapa nilai floating-point (biasanya dalam rentang –1 hingga 1 atau 0 hingga 1). Sebagai ilustrasi, embedding dapat memetakan item makanan seperti "apple strudel" ke koordinat (0.5, 0.3) di kuadran kanan atas dari grafik dua dimensi, sementara "hot dog" berada di kuadran kanan bawah dengan koordinat (0.2, –0.5). Embedding ini memungkinkan kita untuk mengukur kedekatan antar objek berdasarkan jarak dalam ruang vektor. Sebuah alat yang dapat digunakan untuk memvisualisasikan embedding ini adalah Embedding Projector dari TensorFlow, yang memungkinkan kita untuk melihat lebih dari 70.000 kata dalam bahasa Inggris direpresentasikan secara numerik dalam ruang vektor.
Keunggulan utama dari vector embedding ini adalah kemampuannya untuk menangkap kesamaan atau kedekatan sifat antar objek berdasarkan jarak antar koordinat dalam ruang embedding. Kedekatan ini dapat dihitung menggunakan rumus jarak seperti Euclidean distance atau cosine similarity. Salah satu aplikasi embedding yang sangat berguna adalah dalam algoritma pengenalan wajah (face recognition). Idenya adalah bahwa wajah-wajah yang mirip akan memiliki jarak embedding yang berdekatan. Jadi, untuk mengenali wajah seseorang, yang diperlukan hanyalah menghitung jarak antara embedding wajah referensi dan wajah baru. Jika jaraknya cukup dekat (berdasarkan threshold yang telah ditetapkan), maka gambar tersebut bisa dianggap sebagai wajah dari orang yang sama. Algoritma face recognition modern, misalnya dlib bekerja dengan membuat embedding dari fitur wajah dalam ruang vektor laten. Ilustrasi Face Embedding dapat dilihat pada Gambar 2 berikut:
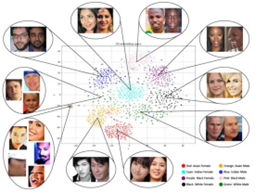 Gambar 2. A two-dimensional t-SNE visualization of Balanced Faces in the Wild (BFW) embeddings (Frisella et al., 2022)
Gambar 2. A two-dimensional t-SNE visualization of Balanced Faces in the Wild (BFW) embeddings (Frisella et al., 2022)
Keywords: Embedding, Machine Learning, Face Recognition, Euclidean Distance
SDG: 9 “Industry, Innovation and Infrastructure”
Referensi:
- https://developers.google.com/machine-learning/crash-course/embeddings/embedding-space
- https://projector.tensorflow.org/
- https://www.cloudflare.com/learning/ai/what-are-embeddings/
- https://platform.openai.com/docs/guides/embeddings
- http://dlib.net/
- https://github.com/ageitgey/face_recognition
- Frisella, M., Khorrami, P., Matterer, J., Kratkiewicz, K. and Torres-Carrasquillo, P. (2022). Quantifying Bias in a Face Verification System. AAAI Workshop on Artificial Intelligence with Biased or Scarce Data (AIBSD), [online] 12, p.6. doi:https://doi.org/10.3390/cmsf2022003006.

Comments :